Platforma CENAGIS to
Dane
Jak są przechowywane dane w CENAGIS?
Poniższy artykuł opisuje technologie wykorzystane do organizacji repozytorium danych CENAGIS.
Dane w CENAGIS to olbrzymi zbiór, zróżnicowany tematycznie i technicznie. Jego opis warto zacząć od pokazania miejsca, które zajmuje w architekturze systemu CENAGIS.
Struktury danych w architekturze systemu CENAGIS zaprojektowano w taki sposób, żeby wykorzystać wszelkie dostępne repozytoria danych przestrzennych. Wzięto pod uwagę ich zróżnicowane zakresy tematyczne oraz odmienne modele danych. Projektując architekturę uwzględniono również wymagania, jakie stawia olbrzymi rozmiar danych i zakładane metody ich wykorzystania przez użytkowników. Z tego powodu dane są osadzane zarówno w relacyjnych jak i nierelacyjnych bazach oraz w systemie plików. Ilustruje to rys. 1.
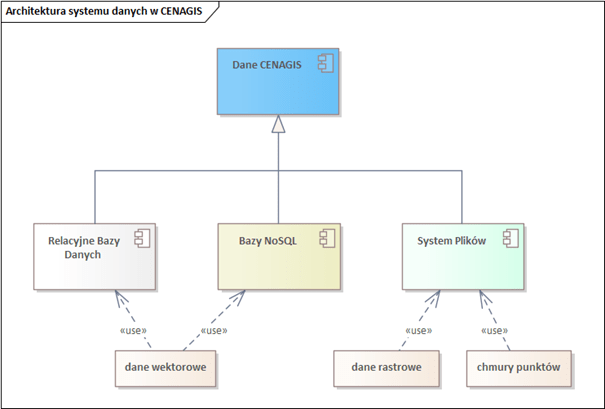
Pierwszym z rozwiązań technicznych są relacyjne bazy danych. Wybrane narzędzie to PostgreSQL z rozszerzeniem PostGIS. Ten silnik baz danych wykorzystywany jest w dwóch obszarach: w centralnym klastrze danych oraz na maszynach klientów – w ich wirtualnych laboratoriach.
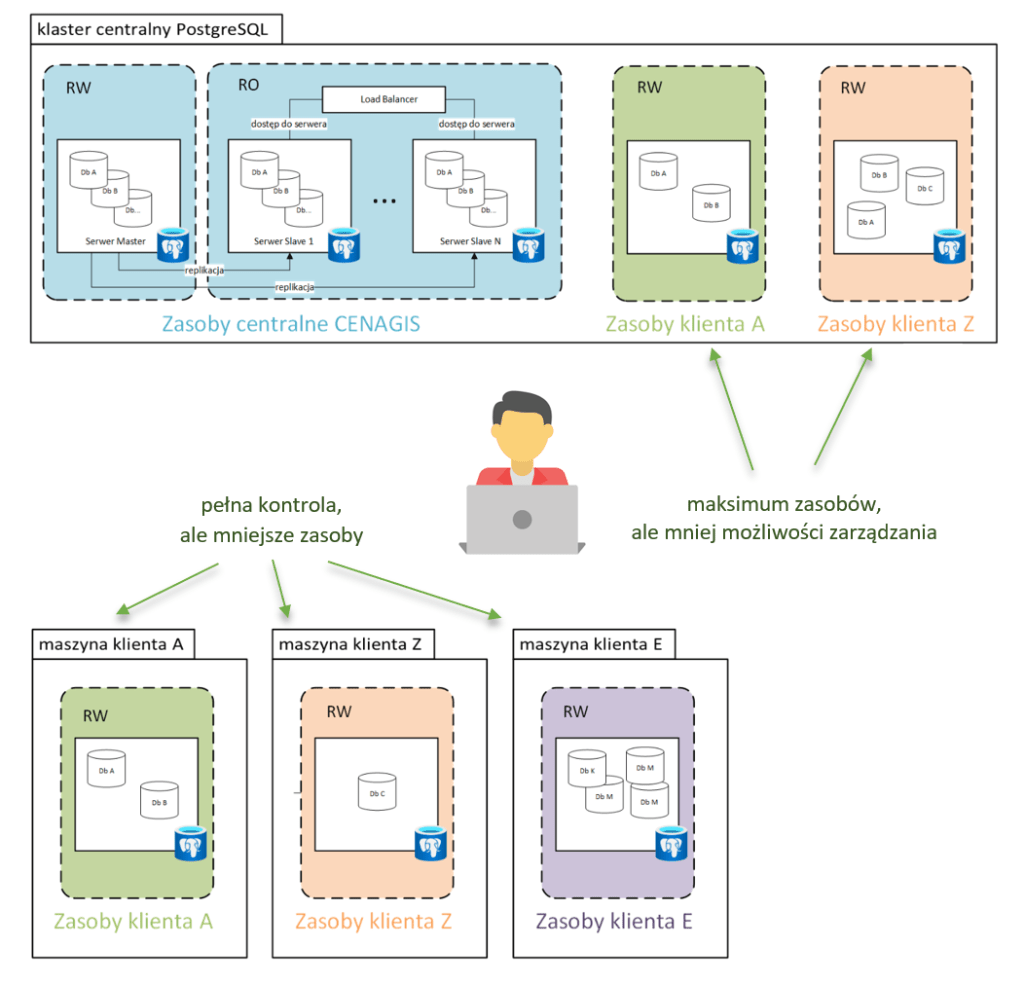
Rys. 2 pokazuje wspomniane obszary W górnej części jest centralny klaster bazy danych. W dolnej części pokazano maszyny wirtualne użytkowników. Klaster (kolor niebieski) to struktura uformowana z kilku maszyn fizycznych, która gwarantuje wysoką efektywność dostępu do danych i ich wysokie bezpieczeństwo. W tym miejscu znajduje się centralne repozytorium danych wektorowych systemu CENAGIS.
Widać tu maszynę oznaczoną jako RW (Read Write), to serwer Master, który pozwala zarządzać centralnym repozytorium. Na prawo od niego jest kilka maszyn Slave, do których dane są replikowane z serwera Master.Użytkownik ma dostęp do tych maszyn w trybie Read Only. Z jego perspektywy oczywiście struktura ta jest widoczna jako jeden magazyn.
W klastrze centralnym widać też osobne pozycje o barwie zielonej i pomarańczowej. Oznaczają one bazy, które mogą zostać założone w na życzenie użytkownika. Do tych baz dane zostaną przekopiowane w trakcie procesów ETL realizowanych przez użytkownika, albo (na jego zlecenie) przez pracowników CENAGIS.
W dolnej części pokazano symbolicznie maszyny klientów, na których będą preinstalowane serwery PostgreSQL. Kiedy użytkownik powinien się decydować na zakładanie bazy w klastrze centralnym, a kiedy na swojej maszynie? To zależy od planowanych przez niego działań i wynikających z tego potrzeb.Decydując się na postawienie bazy w obszarze serwera centralnego zyskuje się na wydajności (wykorzystuje się zasoby klastra skonfigurowanego do pracy pod dużym obciążeniem), traci się jednak wiele przywilejów, które chciałoby się mieć jako administrator bazy danych. Decydując się na postawienie bazy na swojej maszynie Wirtualnej traci się na wydajności, ale zyskuje się możliwość pełnej kontroli administracyjnej swojej bazy.
Relacyjne bazy danych służą do przechowywania danych wektorowych w ściśle określonej strukturze. CENAGIS jest systemem BIG DATA, czyli dającym możliwość analiz z wykorzystaniem obliczeń rozproszonych w Apache Spark i Hadoop na wielkich zasobach danych. W tym podejściu relacyjne bazy danych się nie sprawdzą. Rozwiązaniem jest GEOMESA czyli oprogramowanie GIS współpracujące z Apache Spark i Hadoop. GeoMesa do przechowywania danych wykorzystuje bazę typu NoSQL – Accumulo. Bazy typu NoSQL to bazy działające w architekturze rozproszonej, których model danych nie jest modelem relacyjnym.
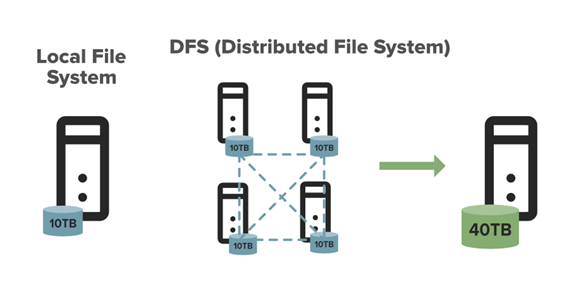
Dane o modelach innych niż wektorowe, czyli rastry i chmury punktów składowane są w systemie plików. W CENAGIS wykorzystano rozwiązanie Hadoop Distributed File System (HDFS). Jest to rozproszony system plików, który przechowuje dane na zwykłych maszynach, zapewniając bardzo wysoką łączną przepustowość w całym klastrze.
HDFS jest specyficzny w obsłudze. Kopiowanie, usuwanie danych realizuje się tu oddzielnym zestawem komend (nieco podobnym do znanego z z Linux). Zetknie się z tym jednak tylko użytkownik zaawansowany – np. w Jupyter Hub. Zwykły użytkownik, który po prostu chce wykonywać analizy GIS na swojej maszynie wirtualnej tego nie zauważy. Dla niego zasoby zostały zmapowane w sposób, który pozwoli na dostęp z użyciem standardowych technik znanych z systemu Windows.
Dostęp użytkownika do danych różni się w zależności od ich modelu i rodzaju struktury, w której zostały osadzone.
W trakcie wyszukiwania danych użytkownik będzie mógł przeglądać metadane i dane poprzez aplikacje wykorzystujące technologie CKAN, Geonetwork, Terria, ERDAS Apollo.Skąd użytkownik CENAGIS się dowie z jakich danych może korzystać, jak postępować, żeby je pozyskać, jakimi narzędziami to robić? Dowie się tego z dokumentacji (wiki, przewodniki dostępne z panelu dostępowego CENAGIS).
Do danych z relacyjnych baz danych użytkownik dotrze m. in. poprzez łącza, które zostały zdefiniowane w aplikacjach GIS zainstalowanych na szablonach maszyn wirtualnych. Warto przy tym wspomnieć , że model danych, z których korzysta użytkownik w CEANGIS jest profilowany również pod kątem oprogramowania, z którego się korzysta. Np. dla użytkowników oprogramowania ESRI utworzono osobne repozytoria tzw. geobaz enterprise. Dla użytkownika, który chce posługiwać się językiem SQL na każdej maszynie jest zainstalowany pgAdmin – klient do osbługi bazy PostgreSQL. Użytkownicy Jupyter Notebooks mogą posługiwać się językiem Python z wbudowaną biblioteką psycopg2.
Dostęp do danych big data wymaga większych umiejętności informatycznych. Oprogramowanie do analiz Big Data korzysta z danych w HDFS i z baz Accumulo. Użytkownik środowiska Big Data CENAGIS nie ma bezpośredniego dostępu do bazy Accumulo. Praca ze środowiskiem Big Data odbywa się za pośrednictwem Jupyter Notebook, w którym za pomocą języka Python można zlecać operacje na danych w GeoMesa.


Lista dostępnych danych
Dane wektorowe
- Baza Danych Obiektów Topograficznych BDOT10k,
- dane budynków 3D z projektu CAPAP,
- Ewidencja Gruntów i Budynków (budynki, działki),
- Państwowy Rejestr Granic (jednostki administracyjne, granice specjalne, ulice, punkty adresowe),
- Państwowy Rejestr Nazw Geograficznych (nazwy miejscowości, obiektów fizjograficznych).
- Bank Danych o Lasach (min. granice jednostek administracji lasów, wydzielenia)
- dane z SDI (min. korytarze ekologiczne, mezoregiony, obszary chronionego krajobrazu, obszary specjalnej ochrony, parki narodowe i krajobrazowe, rezerwaty, pomniki przyrody …),
- CORINE,
- dane z monitoringu wody i powietrza.
- jednostki podziału statystycznego kraju,
- dane o ludności ze spisu z 2021,
- Bank Danych Lokalnych.
- stacje/posterunki pomiarowe, dane z obserwacji meteorologicznych.
- pomniki historii, obiekty UNESCO, zabytki architektury, zabytki nieruchome.
- mapy zagrożenia powodziowego, mapy ryzyka powodziowego.
- dane min. o stacjach BTS, kolokacjach, hot-spotach, liniach, węzłach, usługach, planowanych inwestycjach.
- dane (dwa modele danych),
- serwis mapowy,
- serwisy do routingu,
- serwis do geokodowania.
- OpenCell ID (baza danych o nadajnikach sieci komórkowych),
- GDELT
Dane rastrowe
- ortofotomapy
- aktualne i archiwalne,
- w rozdzielczościach <10 cm, 10 cm, 25 cm, 50 cm, >50 cm (archiwalne),
- dane wysokościowe ze skaningu laserowego
- Numeryczny Model Terenu, rozdzielczość 1 m,
- Numeryczny Model Pokrycia Terenu, rozdzielczość 0.5 m (miasta), 1 m (pozostałe),
- modele zgeneralizowane,
- modele pochodne (np. mapy spadków).
- Sentinel-1, Sentinel-2, Sentinel-3, Sentinel-5P – całość archiwum, obszar Europy,
- Landsat 5 (1984-2011), Landsat 7 (1999-2017), Landsat 8 (2013-teraz) – obszar Europy,
- Envisat (2002-2012), SMOS (2010-teraz) – cały świat,
- Jason-3,
- dane serwisów tematycznych Copernicus – Atmosphere, Climate, Emergency, Land, Marine,
- baza danych typów pokrycia terenu S2GLC,
- NMT (Mapzen, SRTM, Copernicus).
Chmury punktów
- Dane pomiarowe ze skaningu laserowego w formacie *.laz
- Zintegrowane dane dla obszaru całej Polski w formie Cesium 3D Tiles